[Database] - 트랜잭션의 격리 수준
- 지난 포스팅에서는 트랜잭션 스케줄의 개념과 순차적으로 실행되는 Serial 스케줄, 그리고 Serial 스케줄과 동일한 결과를 산출할 수 있는 Serializable 스케줄에 대해 Conflict Serializability와 View Serializability의 개념을 바탕으로 살펴봤습니다. 이번 포스팅에서는 Serializable 트랜잭션의 격리 수준 개념에 대해 살펴볼 예정입니다.
격리 수준(Isolation Level)
-
트랜잭션의 격리 수준은 트랜잭션들이 동시에 수행되는 과정에서 각 트랜잭션이 다른 트랜잭션의 작업에 얼마나 영향을 받는지를 나타냅니다. 즉, 각 트랜잭션이 얼마나 격리된 상태로 수행되는지를 나타내는 개념으로 이해할 수 있습니다. 격리 수준이 높을수록 트랜잭션이 더 많이 격리된 상태로 수행된다고 볼 수 있습니다.
-
격리 수준은 일반적으로 크게 네 가지로 나뉩니다. 격리 수준이 높은 순서대로 나열했습니다.
- Serializable
- Repeatable Read
- Read Committed
- Read Uncommitted
-
네 가지 격리 수준의 개념을 이해하기 위해서는 먼저 Serializable하지 않은 스케줄에서 나타나는 이상 현상(anomaly)에 대해서 살펴봐야 합니다. 이는 크게 Dirty Read, Non-Repeatable Read, Phantom Read로 구분됩니다.
Non-Serializable 스케줄에서 발생하는 세 가지 이상 현상
-
Dirty Read : 트랜잭션이 아직 커밋되지 않은 다른 트랜잭션의 데이터를 읽어오는 현상을 의미합니다.
-
Non-Repeatable Read : 트랜잭션이 읽어온 다른 트랜잭션의 데이터가 초기와 달라지는 현상을 의미합니다. 예컨대 트랜잭션 A가 트랜잭션 B의 데이터 b를 읽어온 뒤, 잠시 뒤 다시 트랜잭션 B의 데이터 b를 읽어왔는데 그 사이 데이터 b가 수정되었다면 트랜잭션 A의 입장에서는 다시 읽어온 데이터 b의 값이 이전과 달라지는 현상이 발생합니다.
-
Phantom Read : 트랜잭션이 동일한 쿼리를 반복 실행할 때 다른 트랜잭션에서 데이터를 삽입하여 기존에 없던 데이터가 읽혀오는 현상을 의미합니다.
세 가지 이상 현상을 활용해 격리 수준의 개념을 이해해보겠습니다.
Serializable
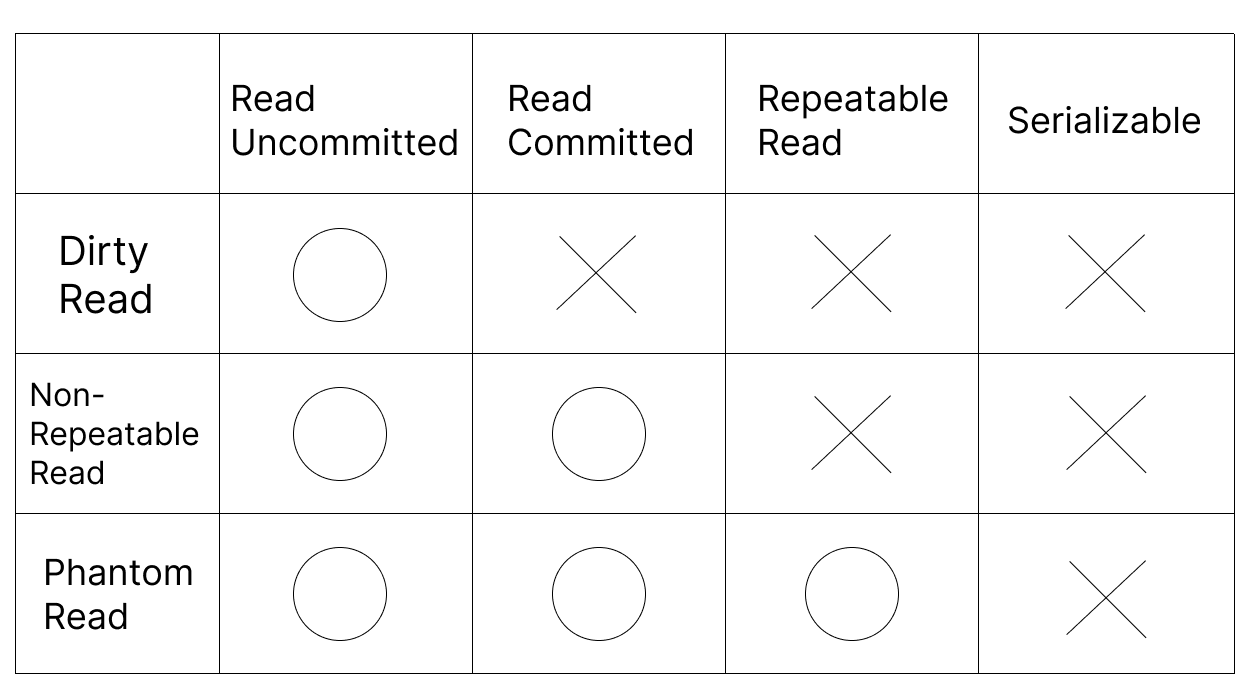
- 가장 높은 단계의 격리 수준입니다. 지난 포스팅에서 확인한 것과 같이 순차적으로 수행되는 Serial 스케줄과 동일한 결과를 산출할 수 있는 스케줄들을 의미합니다. 각 트랜잭션이 순차적으로 수행되는 것과 같은 결과를 산출해야하기 때문에, 동시에 수행되는 트랜잭션들 간에 영향을 주고 받아서는 안됩니다. 따라서 위의 세 가지 이상 현상의 발생을 전부 허용하지 않는 격리 수준입니다.
Repeatable Read
- 오직 커밋된 트랜잭션의 데이터만을 읽어오고, 하나의 트랜잭션에서 다른 트랜잭션의 동일한 레코드의 값을 반복적으로 읽어올 때 동일한 값을 읽어오도록 보장하는 격리 수준입니다. 그 정의에 따라 Dirty Read와 Non-Repeatable Read는 허용하지 않지만, 동일한 쿼리를 실행했을 때 기존에 없던 레코드가 추가되는 현상이 발생할 수 있습니다. 즉, Phantom Read 현상은 발생이 가능합니다.
Read Committed
- 커밋된 트랜잭션의 데이터만을 읽어오도록 보장하는 격리 수준입니다. 그렇기에 Dirty Read는 허용하지 않지만, 이미 읽어온 다른 트랜잭션의 레코드 값에 대해 중간에 수정과 커밋이 이뤄질 경우 기존에 읽어왔던 값과 달라지는 Non-Repeatable Read 현상이 발생할 수 있습니다. 또한 Phantom Read 현상도 발생 가능합니다.
Read Uncommitted
- 가장 낮은 단계의 격리 수준으로, 커밋되지 않은 트랜잭션의 변경 내역도 읽어올 수 있습니다. 그렇기 때문에 Dirty Read, Non-Repeatable Read, Phantom Read가 모두 발생할 수 있습니다.
각 격리 수준별 이상 현상을 표로 정리하면 다음과 같습니다.
정리
- 이번 포스팅에서는 트랜잭션의 격리 수준 개념에 대해서 살펴봤습니다. 다음 포스팅에서는 실제 DB에서 격리 수준 개념이 어떻게 적용되고 있는지 PostgreSQL을 활용하여 살펴보겠습니다.