[알고리즘] - 가장 먼 노드 (프로그래머스)
- 이번 문제는 프로그래머스의 ‘가장 먼 노드’ 입니다. 문제 명세 및 입출력 예시는 링크를 참고해주세요!
접근 방식
- 1번 노드로부터 가장 멀리 떨어져 있는 노드들의 개수를 구해야 하기 때문에, 우선 가장 멀리 떨어져 있는 노드의 깊이를 확인하고, 해당 깊이를 가지고 있는 노드들을 모두 구하는 방식으로 접근했습니다.
- 앞서 풀었던 ‘미로 탈출’ 문제에서 얻은 아이디어를 바탕으로 BFS를 활용할 경우 동일한 깊이(레벨)의 노드들을 파악하는 것이 수월할 것이라고 판단해 BFS 방식으로 탐색을 진행했습니다.
구현
-
노드-간선 입력을 리스트로 받아 구현 시도
-
BFS 함수에서 방문 체크를 위해 사용하는 리스트에 탐색 깊이를 담고, 모든 탐색이 끝난 뒤 해당 리스트를 반환했습니다.
-
탐색 과정에서는 노드-간선을 원소로 하는 graph 리스트를 반복적으로 순회하며 해당 노드와 연결되어 있는 다른 노드를 찾도록 했습니다.
-
해당 리스트에서 가장 큰 값, 즉 가장 깊은 탐색 깊이를 찾아내고, 리스트 안에서 해당 값을 가지고 있는 원소의 개수를 구하도록 했습니다.
from collections import deque def bfs(graph, start_node, visited): visited[start_node - 1] = 0 queue = deque([start_node]) while (queue): target_node = queue.popleft() target_level = visited[target_node - 1] target_level += 1 for vertex in graph: if vertex[0] == target_node and visited[vertex[1] - 1] == -1: queue.append(vertex[1]) visited[vertex[1] - 1] = target_level elif vertex[1] == target_node and visited[vertex[0] - 1] == -1: queue.append(vertex[0]) visited[vertex[0] - 1] = target_level return visited # 노드들의 거리를 가지고 있는 리스트 def solution(n, edge): cnt_lst = [-1] * n answer = bfs(edge, 1, cnt_lst) # 가장 긴 거리를 가지고 있는 노드의 갯수를 구하는 과정 max_val = max(answer) cnt = answer.count(max_val) return cnt -
그러나 노드 - 간선 입력을 리스트로 처리하자, 큐에서 나온 각 노드들이 자신과 연결된 노드를 찾는 과정에서 모든 그래프 내부를 다 순회하게 되었고, 이는 O(n^2)의 시간 복잡도를 갖게 되었습니다.
-
결국 프로그래머스 채점 시스템에 의해 시간 초과가 발생했습니다.. ㅠ
-
-
노드 - 간선 입력을 사전(dictionary)로 변환하여 구현 시도
-
앞선 방식과 동일한 흐름에서, 매번 graph에서 모든 vertex를 꺼낸 뒤 해당 vertex가 큐에서 꺼낸 노드에 해당하는지 확인하는 과정을 줄이기 위해 노드 - 간선 입력을 dictionary로 변경한 뒤 사용했습니다.
from collections import deque def bfs(graph, start_node, visited): visited[start_node - 1] = 0 queue = deque([start_node]) while (queue): target_node = queue.popleft() target_level = visited[target_node - 1] target_level += 1 if target_node not in graph: continue tnode_list = graph[target_node] for node in tnode_list: if visited[node - 1] == -1: queue.append(node) visited[node - 1] = target_level return visited # 노드들의 거리를 가지고 있는 리스트 def solution(n, edge): cnt_lst = [-1] * n # edge를 dictionary로 변경 edge_dict = {} for e in edge: e1, e2 = e if e1 not in edge_dict: edge_dict[e1] = [] if e2 not in edge_dict: edge_dict[e2] = [] edge_dict[e1].append(e2) edge_dict[e2].append(e1) answer = bfs(edge_dict, 1, cnt_lst) # 가장 긴 거리를 가지고 있는 노드의 갯수를 구하는 과정 max_val = max(answer) cnt = answer.count(max_val) return cnt -
위의 코드와 같이 입력으로 주어진 edge의 각 요소를 순회하며 각 노드를 key로, 해당 노드와 연결되어 있는 노드들의 리스트를 value로 하는 dictionary를 만들었습니다.
-
이에 따라 BFS 함수 내에서 큐에서 나온 모든 노드들에 대해 해당 노드와 연결된 노드들을 찾는 과정에서 시간을 압도적으로 줄일 수 있었습니다.
-
dictionary의 경우 사전 자료형으로, 내부적으로 해시 테이블을 활용함에 따라 검색과 수정에 있어서 O(1)의 시간복잡도만이 소요됩니다.
-
-
실제로 아래 프로그래머스의 테스트 별 시간을 비교해보면, 복잡도가 높은 테스트가 진행됨에 따라 딕셔너리를 활용한 코드(좌)가 리스트를 활용한 코드(우)에 비해 기하급수적으로 빨라지는 것을 확인할 수 있었습니다.
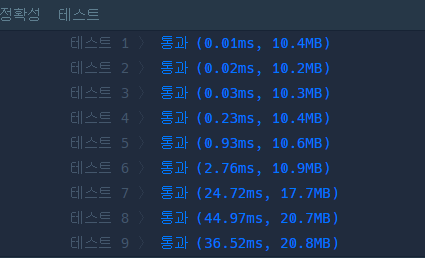 |
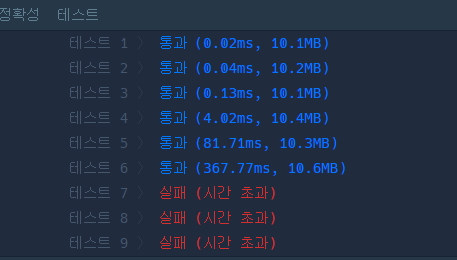 |
Lesson
- 이번 문제를 풀면서, 그동안 dictionary의 힘을 간과하고 있었다는 생각이 들었습니다. 대부분의 문제를 리스트로 처리하다 보니, 특정 요소를 검색함에 있어 딕셔너리라는 매우 효율적인 자료형을 생각조차 하지 못했다고 있었음을 느꼈습니다. 앞으로 문제를 풀면서는 해당 문제와 접근 방식에 어떠한 자료구조가 효율적일지를 고민하는 습관을 들여야겠습니다.